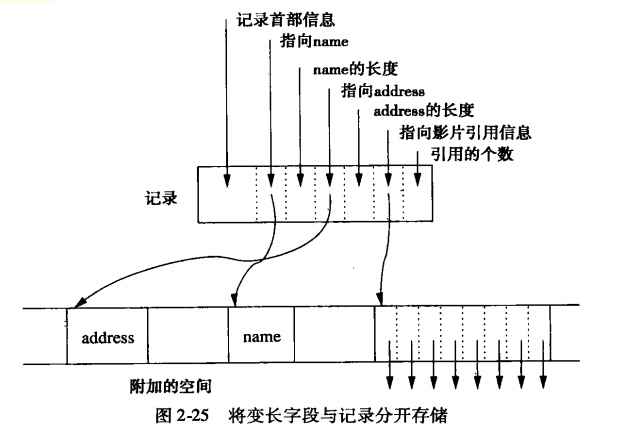
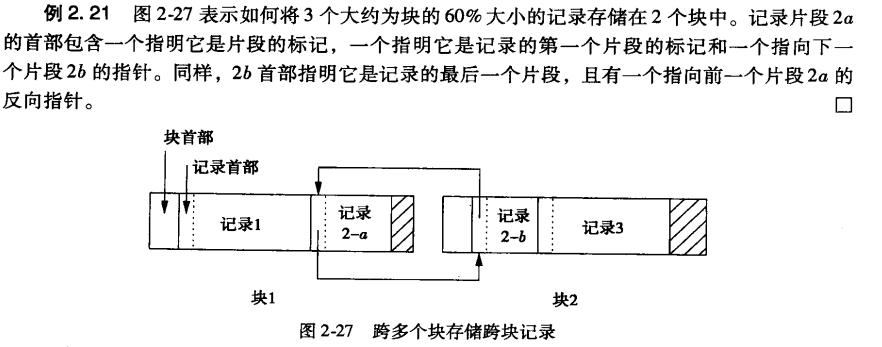
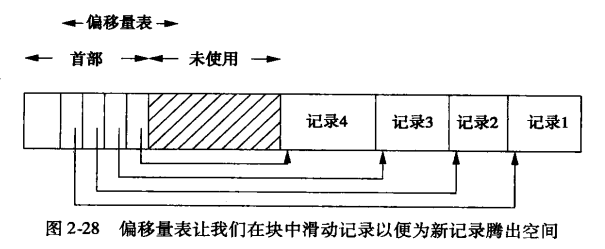
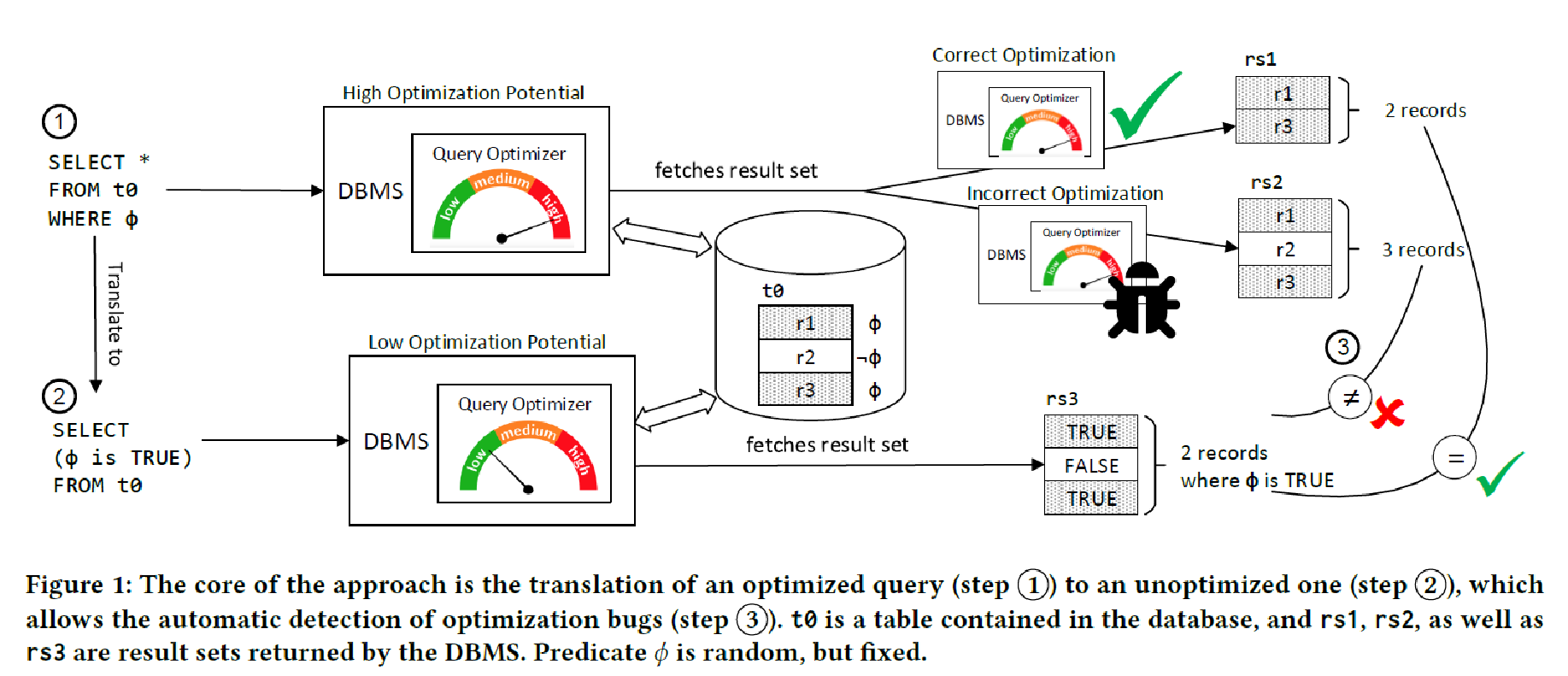
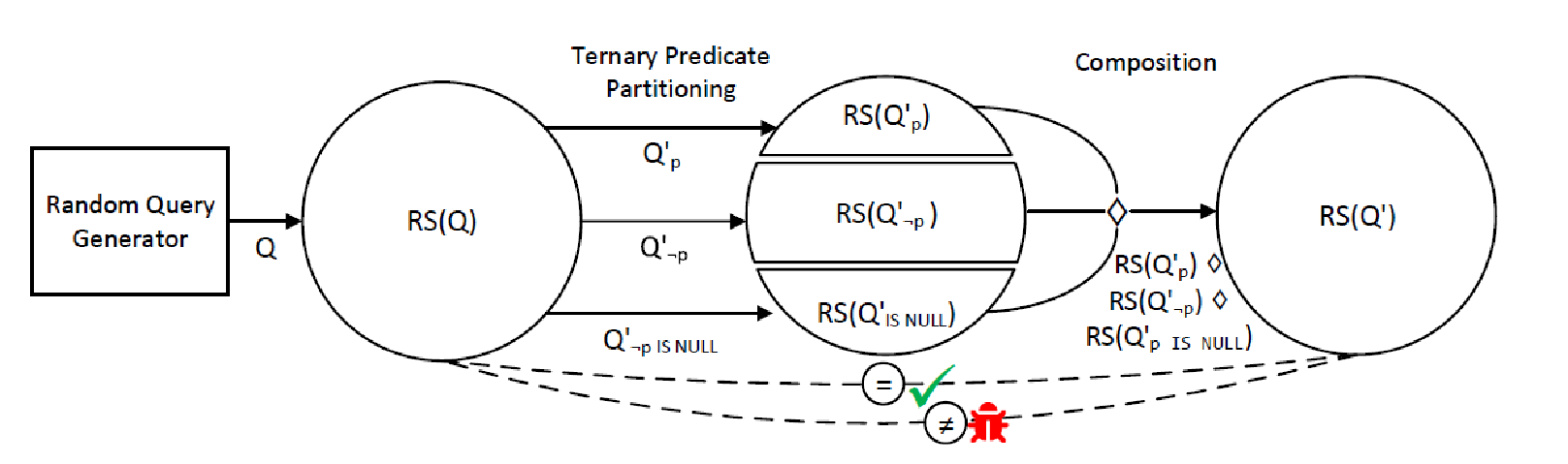
先导
为什么需要NewSQL?
- 数据的急速扩增,需要数据库具有很强的扩展性,往往有两种扩展方式:
- 垂直扩展:scale-up
- 水平扩展: scale-out,采用中间件,做sharding的方式,即分库分表的方式
NoSQL
代表性的DB
- Google’s BigTable — HBASE(开源版)
- Amazon’s Dynamo — Cassandra(开源版)
- MongoDB
- Redis(键值型数据库)
特性
- 不保证强一致性(故不适用金融服务),需要在应用逻辑里处理最终一致性的问题
- 不支持事务
- 数据模型:键值对、图形、文档
NewSQL
特性
- 可扩展性
- 针对读写事务需要满足:
- 执行时间短
- 一般只查询一小部分数据,通过使用索引来达到高效查询的目的,即避免全表扫描或者大规模的分布式join
- 一般执行相同的命令,使用不同的输入参数
数据库的历史
early 1970s
- IBM’s SystemR
- the University of California’s INGRES
- Oracle(和系统R的设计很像)
- DB2 1983
late 1980s and early 1990s
- 出现面向对象的数据库(但夭折了),不过他的思想延续了,如加入对象和XML
- MYSQL 1995
- PostgreSQL 1994
2000s
- 2000s,随着互联网的应用越来越多,对数据库的要求也高起立了,针对这个,有一部分人提出将数据库scale-up,一直更新数据库的硬件资源,不断升级。
- 另一部分提出了使用一个定制的中间件,在一组便宜的机器上构建单节点的DBMS,主要是中间件的功劳!!(感觉这个接近现在newsql的概念),中间件需要做的事情可多了,对应用端不偏于访问数据库的queries进行重写,之后再发给底下的机器上,让它们执行完返回,之后中间件再结合它们的合并他们的返回结果给应用端。能力大了,担子也就自然大了,因此导致中间件这个节点负载过大,产生性能瓶颈(这是我自己的想法)
- 中间件的典型:
- Google’s MySQL-based cluster(这方法被Facebook采取,至今仍在使用)
- eBay’s Oracle-based cluster(join贼不方便。ebay要求开发人员在应用层自己去实现Join)
- 中间件的典型:
- 最终,提出分布式DBMSs,因为传统数据库关注一致性和正确性的同时,忽视了可用性和性能,但这种trade-off对于如今的互联网应用来说却是不合适的。而且使用full-featured DBMS(像MySQL)开销很大(限制太多)
mid to late 2000s
- NoSQL出现了,他们放弃了强事务保证和传统数据库中的关系模型,选择了最终一致性和可选择的数据模型(key/value,graphs,documents)
- 代表:
- Google’s BigTable(未开源)
- Amazon’s Dynamo(未开源)
- Facebook’s Cassandra(基于BigTable & Dynamo)
- PowerSet’s Hbase(基于BigTable)
- MongoDB
- NoSQL的好处是开发人员会更关注他们的应用场景而并非如何去扩展数据库
- 但一些机构(如Google)发现NoSQL会导致他们的开发人员耗费太长时间去处理数据一致性和事务。这些机构职能要么去scale-up机器,要么使用他们自己的定制化的中间层去支持事务。
NEWSQL
- 既想拥有NoSQL一样的可扩展性,又想保持传统数据库中的关系模型和事务支持
- NewSQL DBMSs 读写事务的特点:
- short-lived
- 只用到少部分的数据集(使用索引)
- 事务模板重复(只修改输入参数值)
- NewSQL 有更狭窄的定义:
- a lock-free concurrency control schema
- a shared-nothing distributed architecture
NewSQL的分类
- 使用新架构的新系统
- 重新实现2000s由Google等开发的中间层基础设施
- 由云计算提供的数据库即服务
注:以上的这些之前都提出新的存储引起去取代mysql默认的innoDB,只改变引擎的话就不需要改变API,但是作者认为mysql的InnoDB可靠且性能好,如果改变InnoDB的存储引擎是为了将行存换成列存,如OLAP的话是可以接受的(如Infobright,InfiniDB)。但还是OLTP事务的话换掉InnoDB引擎是没有什么意义的。
新的架构
- 都有以下几个特征:
- 基于分布式架构在shared-nothing resources,且包括以下组件:支持多节点并发控制、冗余容错、流控制、分布式查询处理,且包括节点之间的查询优化和交流协议(如节点和节点之间直接send intra-query data,不需要经过统一的中间层)
- DBMSs都自己管理他们的主要存储(无论是在内存还是在磁盘上),不依赖HDFS等系统,这个特性是为了实现query落在数据节点,减少传送代价。
- 当然也有缺点,新的架构想必采用了新的技术,但对于这些技术大多人都不熟悉,那对应的管理数据库和报告工具也就还没有啦~针对此,Clstrix和MemSOL和MYSQL wire protocol维持兼容性。
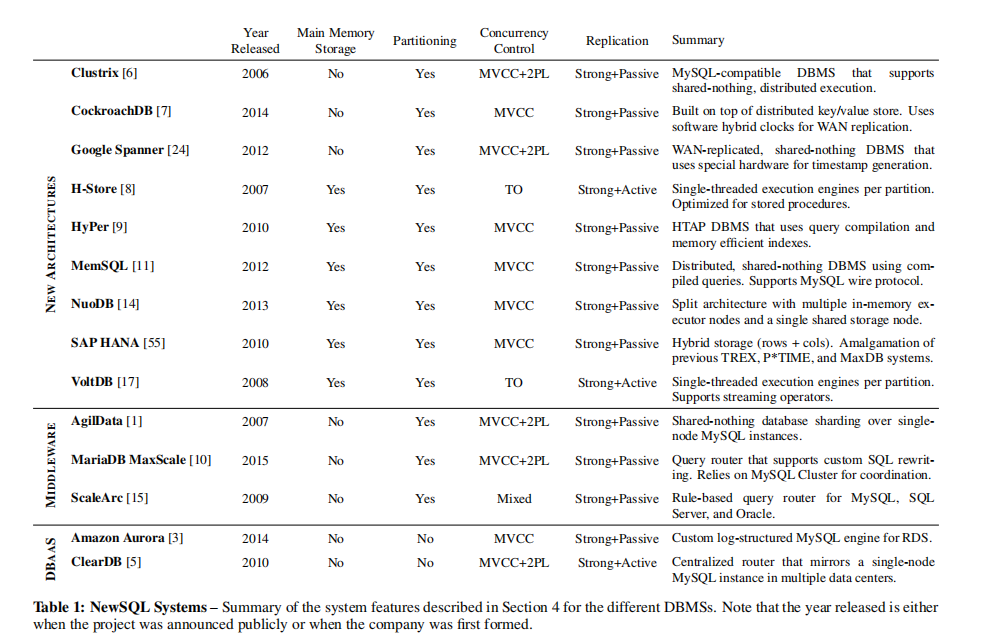
- 本类案例:Clustrix, Cockroach, Google Spanner, H-Store, HyPer, MemSQL, NuoDB, SAP HANA, VoltDB.
透明的分表中间件
- 分表的特性:
- 每个节点都跑同一个数据库
- 每个节点仅是数据库的一部分
- 每个节点都不能被应用独立访问
- 中间件组织查询,安排事务,管理每个节点的数据分布、复制、分割。
- 有个shim layer装在每个数据库节点上和中间层交流,它主要负责代表中间件去执行本地的查询并返回给中间件结果。
- 中间件的优点:使用人员都感觉使用的是同一个节点的数据库。
- mysql就使用中间件去扩展,因此中间件需要支持mysql wire protocol
- 很多组织的确是使用了中间件,但每个节点都使用传统的数据库(如mysq),这样他们都不能使用存储管理器或者并发控制schema。而且中间件不得不先去优化一下查询计划再分发给不同的数据库节点。(每个节点自己也会优化中间件派发给自己的查询)
- 本类案例:AgilData Scalable Cluster, MariaDB MaxScale, ScaleArc, ScaleBase.
数据库即服务
- 如今,很多云计算都提供NewSQL 数据库即服务,也就是开发人员不需要自己去配置资源等等啥的,只要会使用就好了。交付给用户的只是一个连接DBMS的URL,以及一个用于监控的仪表盘页面或者一组用于系统控制的API。
本文只认为在2016年止只有两款可以认为是NewSQL,分别是Amazon’s Aurora(利用日志结构存储管理来优化I/O并发度)和ClearDB提供定制化的DBaaS部署在主要的云平台上。【不太清楚ClearDB】
本类案例:Amazon Aurora,ClearDB
NewSQL的新技术
主存存储器
- 基于内存存储的NewSQL DBMS有学术的(H-Store,HyPer)也有商用的(MemSQL,SAP HAHA,VoltDB)
- 将数据库全部存储在内存上实质在1980s就被提出来了,那个时候,PRISMA/DB(首个分布式内存DBMS也被开发出来了),Altibase,Oracle’s TimesTen,AT&T’s DataBlitz是其组件。
- 基于内存存储器的NewSQL新就新在它可以将数据库的一部分(比如冷数据)驱逐到磁盘中,也就是说基于内存存储器的NewSQL也可以支持比内存大的数据库了。
- 实现这个通用方法是使用一个数据库内部的internal tracking mechanism来挑选出冷数据。
- 此外,还有一个方法是EPFL中使用VoltDB的OS虚拟内存页。
- MemSQL,管理器手动创建数据库去以列存的方式存储table。它以log-structured storage方式去减少update的开销。
分库分表
- 最早的分布式数据库是SSD-1 project 1970,在1980s system R和INGRES也创建了各自的分布式版本,前者是一个shared-nothing,基于磁盘的分布式数据库,后者由于它的动态查询优化算法得以出名,它把分布式查询切割成小块。
- 但以上分布式数据库都没有啥进展有以下两点原因
- 机器太贵了,分布式机器代价大
- 那个时候由于应用都很简单,对分布式高性能的数据库没什么追求。
- partition怎么做?
- 将数据库的table水平分到几个节点中,可以根据数据的columns,或者具体的values(如根据一个customer的id,做个range or hash partitioning分在节点中,然后对应的order啥的也根据id进行划分,这样尽可能保证一个事务在一个节点上进行查询,避免分布式事务),但是Amazon Aurora,ClearDB去不支持这样的partition【为啥呢】
- 据库schema可以转换为树状结构,树的后代与根具有外键关系。然后依据这些关系关联的属性对表进行分区,使得单个实体的所有数据都能位于同一分区。例子:一个树的根节点可能是一个客户表,数据库将会根据每一个客户进行分区,将每个人的订单记录和账户信息存放在一起。
- 有两种cluster node架构,分别是同质的和异质的
- 同质:数据和执行都放在一个节点上。
- 异质:数据和执行节点分离
异质节点架构
NuoDB
存储节点(SM):将数据库分为多个blocks(atoms)
事务引擎节点(TEs):作为atoms的内存缓冲
- 需要write-locks on tuples,然后对tuples的修改都会去广播给其他的TEs和SM
- 为避免nodes之间的来回,NuoDB公开负载均衡schema确保使用的数据会驻留在同一个TE中
- 和其他的分布式数据库一样都需要partitioning schema,但不需要pre-partition数据库以及定义table之间的关系(为啥不需要?)
MemSQL
只具备执行功能的聚合器节点和存储实际数据的叶节点
execution-only aggregator nodes:不缓冲任务数据
- 存储真实数据的叶子节点:会执行部分queries,从而也减少返回给aggregator节点的数据。而在NuoDB中SM就只是存储数据的节点。
实时迁移
- 物理资源会迁移数据,和NoSQL中的re-balancing很像,但在迁移的过程中NewSQL会确保事务的ACID。有两个方法保证实现这点。
- 以粗粒度的虚拟(逻辑)分区来组成数据库 分布在不同的物理节点上。当DBMS需要re-balance的时候,就移动节点之间的这些虚拟分区。
- Clustrix(NewSQL),AgilData(NewSQL),Cassandra(NoSQL),DynamoDB(NoSQL)就使用这个方法。
- 执行细粒度的re-balancing通过range partitioning重新分配tuples和tuples组。很像MongoDB中的auto-sharding feature。ScaleBase和H-Store常用这方法。
- 以粗粒度的虚拟(逻辑)分区来组成数据库 分布在不同的物理节点上。当DBMS需要re-balance的时候,就移动节点之间的这些虚拟分区。
并发控制
- 需要保证原子性和隔离性
- 主要有两种协调器:集中式或去中心化事务协商
- 集中式的:由一个协调器节点专门管这个事情,所有事务操作都要经过它。在1970-1980s的TP monitors这个方法就被提出了
- 去中心化的:每个节点都保持一定的事务状态(访问其节点数据的),节点之间会相互协商来避免并发事务冲突。
- 优点:便于scalability
- 缺点:需要记录DBMS节点的时钟来保证高同步,从而生成全局有序的事务。
分布式架构
2PL
- SSD-1 由中心化的协调器管理shared-nothing nodes。
- IBM’s R*是去中心化协调器协调的,它使用了分布式的2PL协议,这样事务可以锁定正在访问的节点中的数据项。
- INGRES的分布式版本使用去中心化的2PL以及中心化的死锁检测。
- 现在基本所有NewSQL都避开使用2PL,使用多版本时间戳排序。
MVCC
- MVCC既确保事务之间的竞争,也允许long-running,read-only事务不会阻塞writers。
- MemSQL,HyPer,HAHA,CockroachDB使用这个协议,他们对这个协议也各自做了工程上的优化和调整
2PL&MVCC
- 修改数据库的时候需要去获取锁,修改完一条记录,那么为该记录创建一个新版本,使只读查询可以避免请求锁,因此不会阻塞写事务。
- MySQL’s InnoDB,Google’s Spanner,NuoDB(在MVCC基础上引用了gossip 协议在各节点之中广播版本信息),Clustrix.
- Spanner(及其后代F1和SpannerSQL)使用硬件设备(如GPS,原子时钟)来确保高精度时钟同步
- CockroachDB使用混合时钟协议,结合松散 同步硬件时钟和逻辑计数器
- 所有的中间件和DBaaS服务都继承了它们底层DBMS架构使用的并发控制方案,因为大部分都使用MySQL作为底层DBMS,所以大部分的都是使用的2PL加上MVCC方案。
TO
- VoltDB
- 安排事务在每个分区中一次只执行一个
- 使用混合架构:去中心化方式安排单分区事务,中心化协调器对应多分区事务
- 通过逻辑时间戳对事务进行排序,然后调度它们以便在轮到它们时在分区上执行
- 不足:当事务横跨多个区时,由于网络的交互延迟导致节点等待message的时候空闲。
二级索引(辅助索引)
次级索引包含来自表的不同于其主键的属性集。它允许DBMS支持主键和分区键以外的快速查询。
分布式数据库中二级索引的challenge是他们不能总是像其他的数据库一样以相同的方式进行partition(如直接根据主键进行partition了)。
- 在分布式数据库中支持二级索引的两个设计思想:
- 二级索引存在哪儿
- 如何在事务中维持二级索引
- 中心化的协调器
- 二级索引既在协调器节点,又在shard nodes。
- 优:整个系统中只有单个版本的index,维持起来很方便
- 劣:修改的时候需要修改所有节点上的副本。
- 去中心化的协调器
- 所有基于新架构的NewSQL都是去中心化的,且使用划分好的二级索引
- 每个节点都存储index的一部分。
- 优:修改的时候只需要修改一个节点
- 劣:查询的时候需要去横跨多个节点去找数据在哪儿
- Clustrix:既有replicated,粗粒度的(range-based)index在每个节点上,允许查询使用一个属性(并非partitioning属性找到合适的节点);各个节点上又有第二partitioned index,能根据index找到该节点的tuples。但是都是ranges,而不是单个的值,减少了保持索引副本在集群中同步所需的调度次数。【没太理解】
复制(冗余)
结点间数据一致性
- 强一致的事务,事务的写入必须必须在被确认提交(即持久化)之前被确认并安装到所有副本上。需要使用原子提交协议(2PC)
- 优点:事务读起来方便,各个结点都满足一致性
- 缺点:开销也太大了吧,如果有一个节点失败了,或者网络分区延迟,系统就停着不动了。
两种不同传播的执行模型
active-active 复制
- 每个副本结点都同步执行相同的query
active-passive 复制
- 先在单个结点处理请求,然后将DBMS所得状态传送到其他副本
- 大多数NewSQL DBMS都用这种方式,因为它们使用非确定性并发控制方案。(因为它们可能在不同副本上以不同的顺序执行,并且数据库的状态将在每个副本处出现分歧。因为执行顺序取决于很多因素,包括网络延迟,缓存停滞,时钟偏差等。)
- 确定性DBMS(例如,H-Store,VoltDB,ClearDB)不执行这些附加的协调步骤。因为它们保证事务的操作在每个副本上以相同的顺序执行,从而保证数据库的状态相同。
通过广域网WAN来进行复制
- 因为会引起延迟,所以一般采用异步复制。
- NewSQL系统中只有Spanner和CockroachDB能提供广域网上强一致副本的复制方案。Spanner使用了原子钟和GPS来做时间同步,而CockroachDB使用的是混合时钟方案。
恢复机制
保证数据的更新不会丢失,最小化停机时间
操作:
- 当主节点崩溃时,系统将会自动提升某个从节点充当新的主节点
- 而之前崩溃的主节点重新联机后,需要从新的主节点或者其他副本中更新自己的数据,弥补在停机这段时间内缺失的数据。
两种方法恢复
- 复的节点仍然从自身的存储中加载最后的检查点和写入日志,然后从其他节点读取缺失的日志部分。
- 节点重新联机时丢弃其检查点,让系统给它另一个新的检查点,然后从这个点开始恢复(系统中加入新的副本节点时也可以用同样的机制。)
未来趋势
HTAP
- 分析新数据和历史数据的组合来进行知识推断,获得洞察力
三种方法
分别构建OLAT和OLTP数据库
前端的OLTP DBMS存储所有由事务创建的新数据,而在后端,系统使用ETL(extract-transform-load)工具将数据从OLTP DBMS导入到另一个后台的数据仓库DBMS
所有在OLAP系统中产生的新数据也将会被推送到OLTP库中。
Lambda架构
- 使用单独的批处理系统(例如,Hadoop,Spark)来计算历史数据视图,同时使用流处理系统(例如,Storm,Spark Streaming)来提供输入数据视图
HTAP数据库
前两种方法的问题:
- 数据传输时间开销大
- 部署和维护两种不同DBMS的管理开销巨大
HTAP:结合了最近十年来在OLTP(例如,内存存储,无锁执行)和OLAP(例如,列式存储,矢量化执行 )领域的技术积累,而且只需要一个DBMS。
HTAP例子:
- SAP HANA:在内部使用多个执行引擎,一个用于更适合事务的行数据,另一个用于更适合于分析的列数据。
- MemSQL:使用两个不同的存储管理器(一个管理行,一个管理列),但是混合在同一个执行引擎中。
OLTP转HTAP例子:
- HyPer将H-Store(OLTP)切换到MVCC的HTAP,可以支持更复杂的OLAP查询
- VoltDB将OLTP性能转向提供流式语义【不清楚流式语义】
总结
- NewSQL系统的采用率相对较低,因为NewSQL DBMS的设计目标是支持事务性的工作负载,而这些应用大多数是企业应用(这些比较保守)
- 巨头们更愿意在自己的系统上进行改进和创新,而不是去收购初创的NewSQL公司。2014年Microsoft在SQLServer上新增了内存Hekaton引擎来增强OLTP处理能力。Oracle和IBM的创新进度比较慢,他们最近才为系统添加了列存储扩展,与新兴的OLAP DMBS(例如HP Vertica和Amazon Redshift)展开竞争,并有可能在未来推出内存中的OLTP工作负载处理系统。