主要内容
自动给学生的sql query打分,局部打分,通过判断错误严重的程度。
采用 weighted equivalence edit distance metric,找到最小的编辑序列,能将原始错误的sql query转为正确的query。
使用query规范化规则针对语法和语义进行规划
- 语法,如将Not(A>B) 替换为A<=B; 将操作构建一棵flattened tree
- 语义,将query中主键上的distinct移除,将query中冗余的关系移除。
Flattened Tree Structure
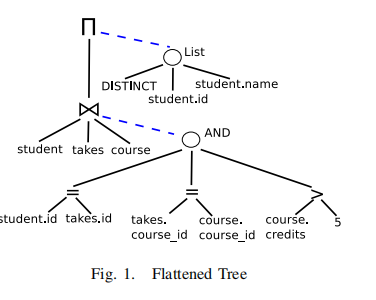
- 将query中有连接关系的都flatten一下,转化为等价形式。
- 针对flattened tree,谓词/投影/聚类操作都作为一棵棵子树
计算规范化的编辑距离
- 对于每个组件(子树)分别计算编辑距离,然后找到每个quert的带权距离。Σc∈componentsWc ∗ Ec
根据编辑距离给分
领域
- 指出错误sql query错在那个部分,也就是做最小的改动,能让sql query变成正确的。
研究常用的方法
- XData通过比较正确query和学生query得到的结果,对学生 sql query进行二分类,即判别正确or错误,但太简单了,想得到更细致的。
- 根据正确query和学生query返回结果交集所占正确结果的比例,但有可能因为一个很小的错误得出的结果很差,导致分数低。
- 学生的sql query需要做多少个变化才能和正确的sql等价,但许多具有语义差异的sql在返回的结果却没什么差异。(本文)针对此,使用大量query规范化技巧移除学生和正确的queries的不相关的语法和语义差别。但是需要给出多个正确的queries,将学生query与其相比较,选出匹配度最高的query。这个问题可以抽象为图中找最短路径,提出一个贪心启发性技巧。
问题
- 基于规范化编辑距离的给分有可能是不公平的,在规范化部分还存在一些问题。
实验部分和讨论部分
随机创建一对不正确的学生queries,a和b,让两个志愿者对每对queries分类,第一类是a queriy的分高,第二类是b query的分高,第三类是a,b query的分数一样高。
potentially an infinite number of edit options are possible
对负载生成的启发点
SQL QUERY 规范化
B. Chandra, M. Joseph, B. Radhakrishnan, S. Acharya, and S. Sudarshan.
Partial marking for automated grading of SQL queries. PVLDB (Demo),
9(13):1541–1544, 2016.