Motivation
- 数据库即服务(DBaaS)目前很流行,云计算的出现,让很多开发人员都直接使用云上数据库而不用自己去搭建一个数据库,这扩展了数据库的使用,但很多开发人员没有数据库相关知识,可能写出来的sql语句存在APs(Anti-Patterns),而APs会影响访问数据库时的性能,进而对应用产生影响。因此,这篇文章站在这个角度,去检测sql语句是否存在APs,并且将sql中存在的APs进行排序(这里主要是为了修复主要影响性能的APs,因为修复APs可能修改数据库schema等等,会对其他的sql产生一定影响),最后对主要的APs进行自动修复(实质上这篇文章是按照现有的规则进行修复)。
Challenge
- AP可能违反基本数据库设计原则(如,参照一致性等等)
Contribution
讲述了如今其他识别APs的工具的局限性
注意:detection是有按照一定的rule进行匹配来将AP侦测出来
Detection:将query和data分析相结合进行AP侦测。
Rank:针对APs上的性能数据进行建模,获取rank model。
Fix:基于规则query重构技术提出fix APs的建议。
Background
Classification of Anti-Patterns
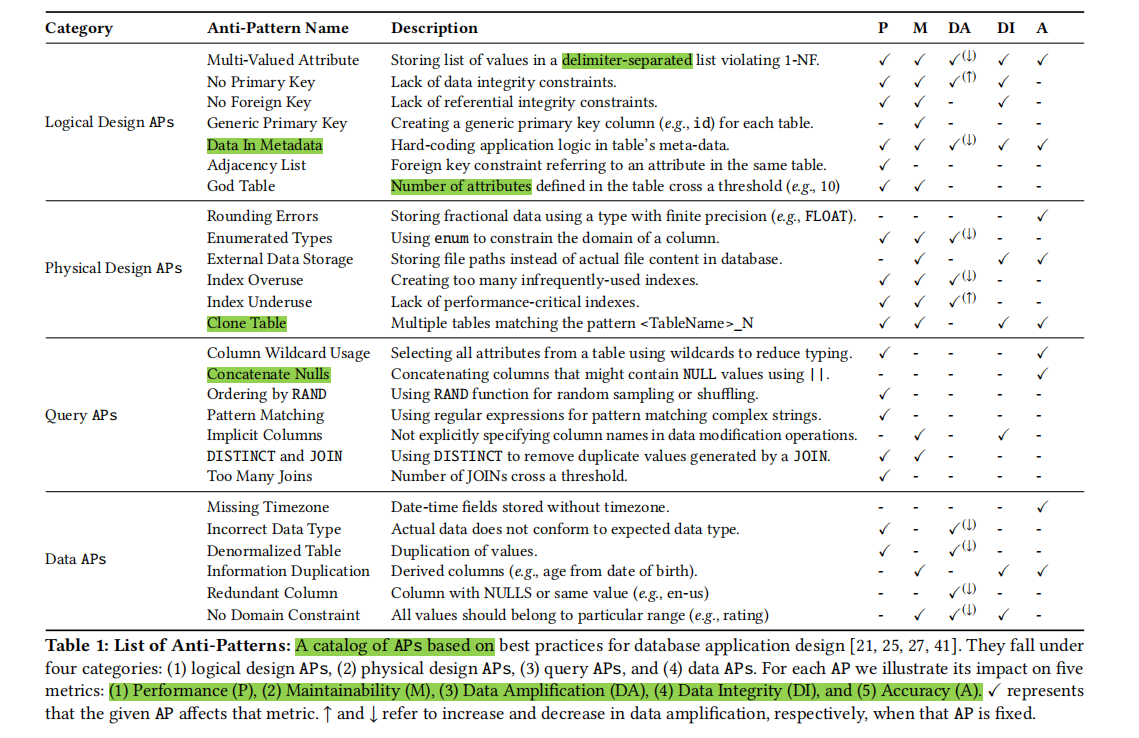
Impact of Anti-Patterns
- Performance:性能,如吞吐和延迟
- Maintainability:当业务发生了改变,应用设计和组件被修改的容易程度(这里指sql和schema)
- Accuracy:存进去的数据和读出来的时候是否还是一致的(如,浮点数的精度是否丢失了,考虑数据库schema的column类型定义的如何)
System Overview
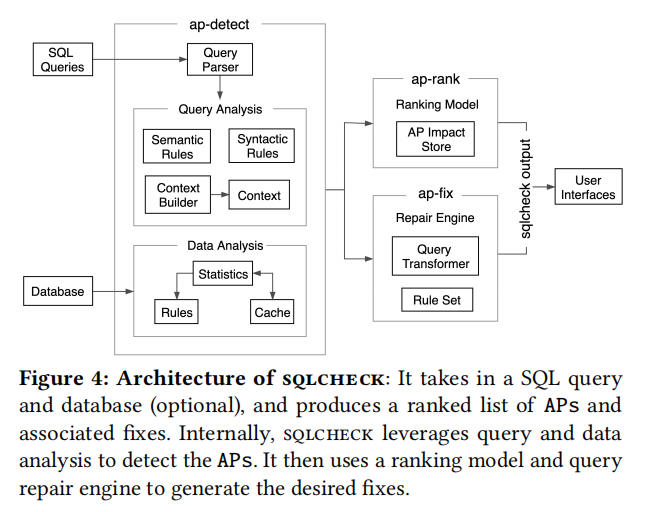
- ap-detect:静态分析queries,分析数据库中的数据和元数据
- ap-rank:根据detect出来的AP对各类评价指标的影响排序(文中设置user-study,由于可以根据自己的应用需求调整不同评价指标的权重,如读事务多的应用场景对读性能更为看重)
- ap-fix:根据定义好的rule来对AP进行fix(也就是说rule是有限的,无法cover到全部,这里detect从后面的实验来看也应该是有限的AP,就是定义的AP越多识别出来的也越多…)
Finding Anti-Patterns
- Query-Analyser:获取query的column name、table names、predicates、constraints和indexes等等(就是一些logical feature)
- Data-Analyser:获取数据库中表的每个Column的数据分布和format(类型?)等
- Query-Rules:根据建立好的rules识别APs判别query是否存在APs
- Data-Rules:根据建立好的rules识别APs判别data是否存在APs

Query Analysis
- intra-query detection:从单条sql获取context,使用预定好的rule(rule里由一系列函数组成)去detect,使用no-validating parsing logic来支持不同数据库的查询,返回annotating the parse tree(ap-detect和ap-fix使用这个去找到APS)
- inter-query detection:从sql和sql之间获取context,利用整个应用的context,不一定是相邻的,在 Intra-query上多包涵了两个组件:schama和与应用相关的queries
Data Analysis
- 首先scan数据库收集【收集代价大,定期执行】:
- tables的schemata
- 数据在相关column上的分布(e.g., unique values,mean, median等等)
- 还是根据相应的规则去check构建好的context中是否存在APs
Ranking Anti-Patterns
Metrics for Ranking Anti-Patterns
- Read and Write Performance (RP, WP):读写性能。通过如果修复好这个AP能获取多少倍的加速。这个指标作为rank依据。
- Maintainability (M):可维护性 是根据支持新的task时,数据库 在存在这个AP和不存在这个AP需要重构时改变的Number的差异,当number高度依赖于应用中的queries数时,这个AP优先级就会很高。
- Data Amplification (DA):冗余的列,如age和出生年月;各种冗余不必要的信息。
- Data Integrity (DI): 更新是否保证数据库中保存的是想要的数据
- Accuracy (A): 如是否满足参照一致性
Model for Ranking Anti-Patterns
- 运用开发人员根据自己的开发需求去设置上方metrics的权重。(实际上开发人员也很难去做到这个,这里可以做一个权重自动化设置工具)
- 当APs之间发生冲突时,即修复一个AP会影响恶化另外一个AP,那就选择优先级高的AP进行修复
Fixing Anti-Patterns
- 自动推荐合适应用场景的数据库设计和queries。

- 两部分的query需要transform: 1. 具有APs的部分 2. 修改APsquery会影响的部分query
- 如果产生模糊的转换,那就返回一个textual fix,就是说这个工具不足够帮你fix…那它告诉你啥textual fix呢,让开发人员自己看着做
- 绿色部分解析: 如果query transformation清晰,那就把它解析成语法树,之后转换成sql语句。(数据库的语法树解析感觉有时间可以看看)
Query Repair Engine
- rule system是可扩展的,开发人员可以自己把rule按照一定的要求加进去。
- 首先,规则系统范式使得ap-fix很容易利用修复规则之间复杂的触发交互,从而避免了显式布局流的需要 规则之间的控制(这里没看懂,就直接有道翻译了一下)
Rule Representation:
- 每条规则都包含一个detection function和一个action function
Implementation
提供了三个接口:
Interactive Shell:
1
2
3
4# Import the anti-pattern finder method
from sqlcheck.finder import find_anti_patterns
query = `INSERT INTO Users VALUES (1, 'foo')`
results = find_anti_patterns(query)
REST Interface
1
2HTTP POST /api/check
Body: {"query":"INSERT INTO Users VALUES (1,'foo')"}
- GUI Interface
扩展性
- 通用的规则接口(name, type, detection rule, ranking metrics, and repair rule)
- context builder:增加应用的context来支持复杂rules
- 用DBMS-specific解析器代替no-validating解析器
Evaluation
与DBDEO进行比较(Digital Equipment Corporation. 1992. SQL-92 Standard.
https://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt.)
Detection of Anti-Patterns
- AP-coverage
- accuary
- Dialect-Coverage:可以适用哪些DBMS
Ranking and Repair of Antipatterns
- 针对几个类型的AP进行讨论
- 索引过度使用
- 索引使用不足
- 不存在外键
- 枚举类型(只有那几个数值)
User Study
- 招募23个学生去
- construst SQL queries
- 使用GUI 界面追踪这些信息:
- the original SQL queries
- the fixes suggested by sqlcheck for the APs detected in the original queries
- the re-formulated SQL queries developed by the user that incorporate these fixes.
- Web Applications & Databases
- 收集github上的sql query,检测人家的应用的query是否存在APs,若存在就在别人的issues中提建议或是给别人发邮件,看看 别人的回馈意见。
- Limitations And Future Work
- 都是根据定好的rules来发现APs的,对于新的不在规则中的APs不能后发现
TOREAD
- Tushar Sharma, Marios Fragkoulis, Stamatia Rizou, Magiel Bruntink,and Diomidis Spinellis. 2018. Smelly relations: measuring and understanding database schema quality. In Proc. of ICSE. ACM, 55–64.
- [21] Cunningham & Cunningham Inc. 2014. C2 Wiki. http://wiki.c2.com/?AntiPatternsCatalog
对负载生成的启发点
- 分析数据特征的时候,获取data在相关列上的分布情况,如Unique values,mean,median等(这里lauca貌似没有使用这些特征)
研究的主要方向
- 与SQL Anti-pattern有关,找到、排序(该APs对性能产生影响的大小)、修复APs
各项性能指标
- Read and Write Performance (RP, WP)
- Maintainability (M)
- Data Amplification (DA)
- Data Integrity (DI)
- Accuracy (A)
基本知识
数据库即服务
- DBaaS是一种云计算服务模型,用户只需要访问数据库即可,无需设置物理硬件,安装软件或配置性能。
- Schemate即schema的复数形式,包括table、column、data type、view、stored procedures、relationships、primary key、foreign key等
Adjacency List
具有层次结构的数据
解决方法:邻接表、路径枚举(Path Enumeration)、嵌套集(Nested Sets)、闭包表(Closure Table)
- 邻接表:在树中检索指定节点的祖先节点是很昂贵的
- 路径枚举:将祖先存储成字符串(以路径的形式),缺点:数据库不能强制规定路径是正确形成的,或者路径中的值对应于存在的节点。维护路径字符串取决于应用程序代码,并验证它的开销是非常昂贵的。
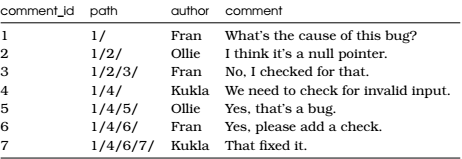
嵌套集:根据深度优先额外维护nsleft和nsright,便于寻找节点的所有祖先节点和所有的孩子结点,但插入和移动节点很复杂,需要重复编号nsleft和nsright,当树的使用设计频繁的插入,嵌套集不是最佳选择。
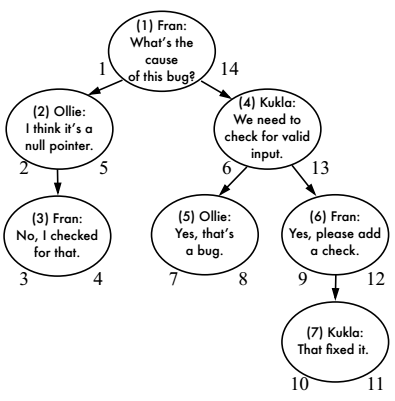

- 闭包表:多增加一个表结构,专门用来存所有的祖孙信息,不只是父子信息,更便于查询。
