- 包括数据库系统实现第一章、第二章、第三章(索引)
数据库管理系统成分
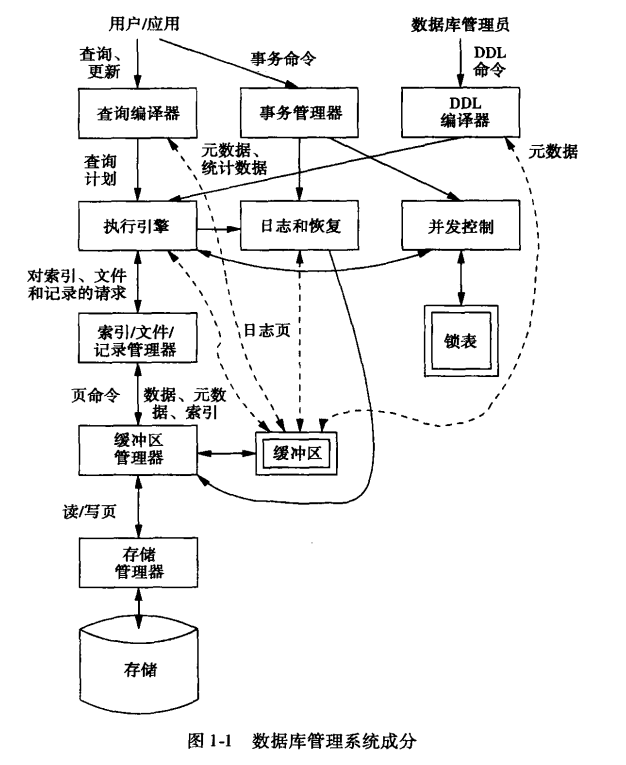
- 分为两大块主要模块:查询响应和事务处理
查询响应
- 先由查询编译器对查询进行分析和优化(如检查语义和语法是否正确、构建语法分析树),选择物理逻辑计划
- 得到查询计划后,传给执行引擎
- 执行引擎向资源管理器请求记录or关系的元组
- 资源管理器掌握着存放关系的数据文件、文件中的数据格式和记录大小,以及支持对于数据文件中的元素进行快速查找的索引文件。查找数据的请求被传送给缓冲区管理器
- 缓冲区管理器与磁盘交互(以磁盘块 单位)
事务处理
- 分为两个主要部分
并发控制管理器
- 负责保证事务的原子性和孤立性
日志和恢复管理器
- 负责事务的持久性
辅助存储管理
存储器层次
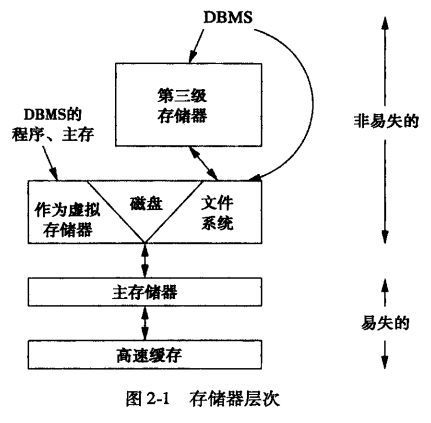
组织磁盘上的数据
- 一般,一个磁盘块中仅存放一个关系的元素
定长记录
- 下图假定所有字段必须以一个4的倍数的字节开始
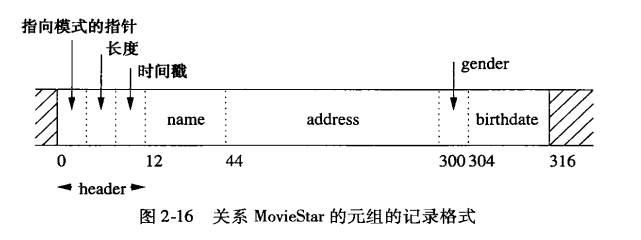

- 当存取或修改记录时,记录(与整个块一起)就被移进主存
- 块首部包含:
- 与一个或多个其他块的链接
- 关于这个块在这样一个网络中所扮演的角色的信息
- 关于这个块的元组属于哪个关系的信息
- 一个给出每一条记录在块内偏移量的“目录”
- 指明块最后一次修改和/或存取时间的时间戳
- 记录长度为316字节,假定4096字节的块,会有292字节的浪费
块和记录地址的表示
- 内存中:与虚拟内存地址相关
- 二级存储器中:与磁盘的设备ID,柱面号等等相关
客户机-服务器系统中的地址
- 服务器:为客户端进程提供二级存储器数据,数据处于数据库地址空间,表示地址的方法有:
- 物理地址(字符串):
- 存储所连接的主机
- 块所在的磁盘或其它设备的标识符
- 柱面号
- 磁道号
- 块号
- 块内偏移量
- 逻辑地址
- 物理地址(字符串):
- 客户端:其地址空间看作主存本身
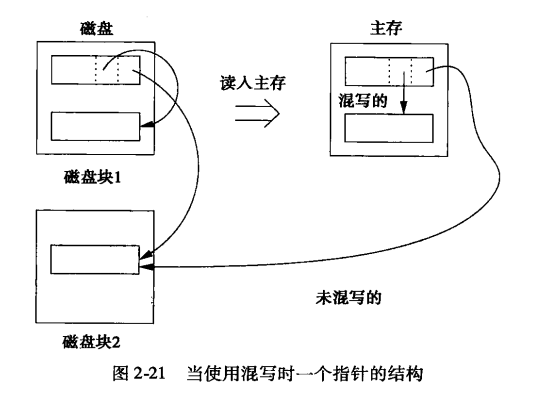
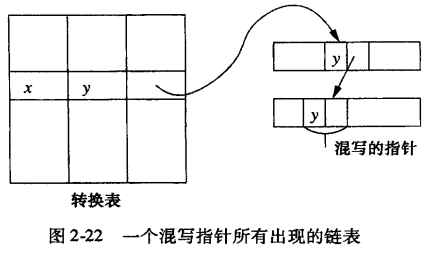
指针混写
- 把块从二级存储器移到主存储器中,块内指针可以“混写”,即从数据库地址空间转换为虚拟地址空间
被钉住的记录和块
- 即内存中一个块当前不能安全地被写回磁盘
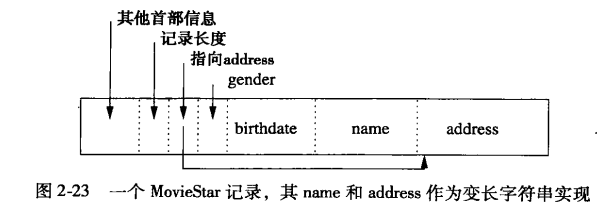
变长数据和记录
变长字段的记录
- 当address地址为NULL时,直接在指向的指针空间处放一个空指针,进一步减少空间。
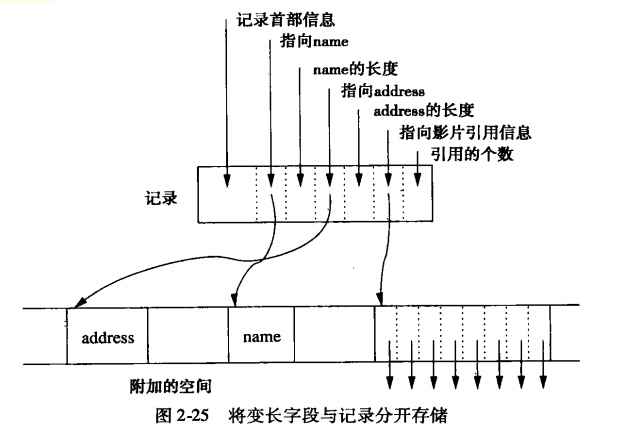
具有重复字段的记录
- 法一:
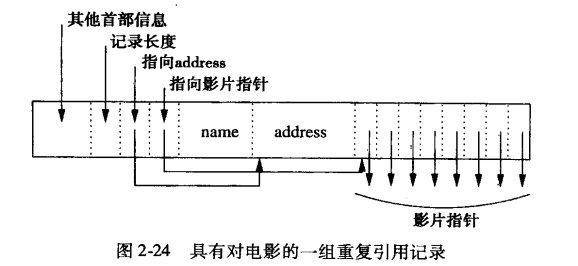
- 法二:
- 保证记录定长,有效对记录进行搜索,但增加 磁盘I/O数目
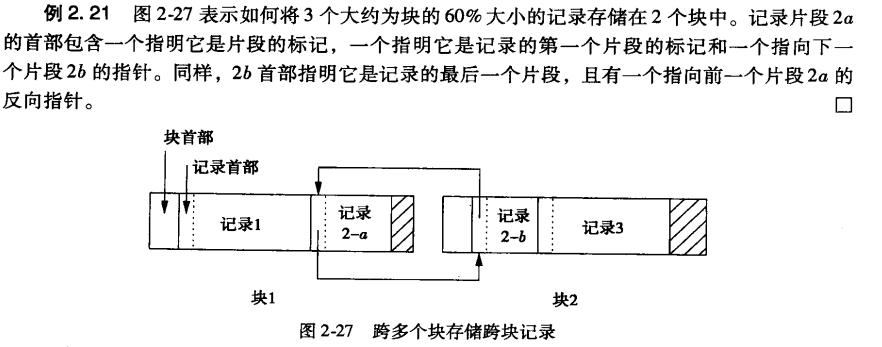
- BOLB(二进制大对象)
列存储
- 适用于:大多数查询请求是针对所有数据或者列的大部分数据。(常用于“分析型”查询)
- 可以与值一起保存元组ID号~
记录的修改
插入
- 元组以某个固定次序存储(如按主键顺序存储)
- 插入的两种方法:(使用偏移量加速找到插入的位置)
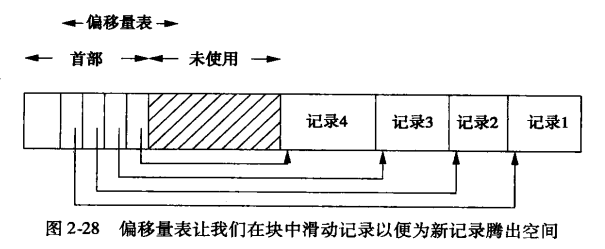
- 在“邻近块”中找空间
- 创建一个溢出块
删除
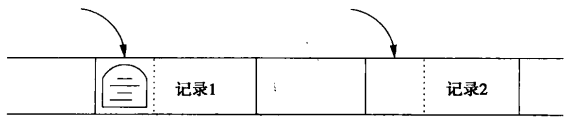
在记录处放删除标志
- 可以是偏移量表中的空指针
- 可以用删除标记代替记录,只用到第一个字节,后续的字节可用于另一个记录~
###
索引结构
基础
主索引&辅助索引:主索引(主键)能确定记录在数据文件中的位置,而辅助索引不能
索引类型:顺序文件(稠密索引、稀疏索引)、B树索引、散列表索引。
稠密索引:为数据文件中的每条记录设一个键-指针对。其中所索引快保持键的顺序与文件中的排序顺序一致。(记录时排好序的)
稀疏索引:为数据文件中的每个存储块设一个键-指针对。(假定数据文件排好序)【只会是主索引】
多级索引:索引文件占据多个存储块,可采用多级索引【主索引】
辅助索引:总是稠密索引,因为不是主键索引(如果该column也不是unique的),那就存在多个相同的索引内容,索引数据跨越多个块。使用辅助索引比使用主索引可能需要多得多的磁盘I/O,但无法解决!
- 避免键值重复:使用桶的间接层
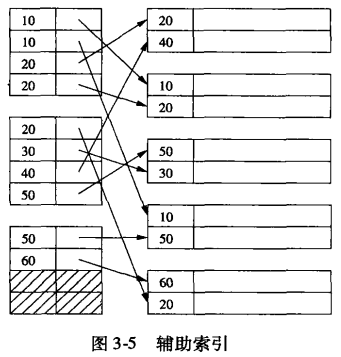
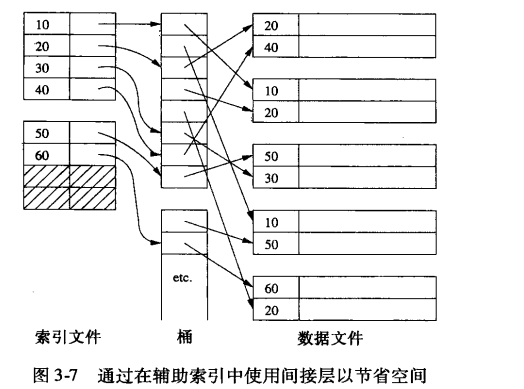
辅助索引的运用:
被组织成顺序文件的关系(如上都是)
作为“堆”结构的主键索引(不太能理解)
聚集文件
1
2
3
4
5
6
7
8Movie(title,year,length,genre,studioName,producerC#)
Studio(name,address,presC#)
Select title,year
From Movie,Studio
WHERE presC# = zzz AND Movie.studioName = Studio.name;(假定这是该应用场景典型的查询)
为这个两个关系建立一个聚集文件结构,在查询键presC#上建立索引。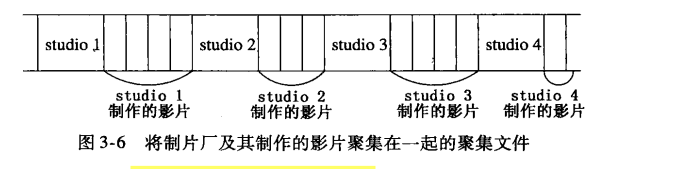
B树索引
- B-树根结点块是永久地缓冲在主存中的绝佳选择。
散列表
插入时,若没有位置,就存储到该块链上的某个溢出块中。
删除时,若块中前一条记录被删除,就一条记录需移动到前面。
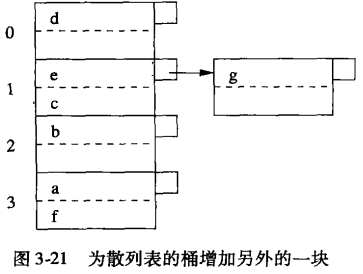
可扩展散列表
动态散列表之一
引入间接层,用一个指向块的指针数组来表示桶,而不是用数据块本身组成的数组来表示桶。
指针数组能增长,长度总是2的幂。
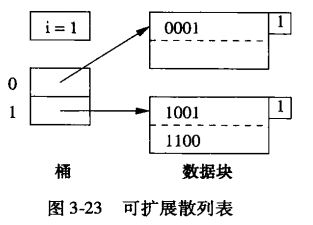
通过判断i和j(右上角小块中的)的大小,不断加倍桶数组,且分裂数据块。
优点:若桶数组小到可以存放在内存中,那么访问桶数组就不需要进行磁盘I/O。
线性散列表
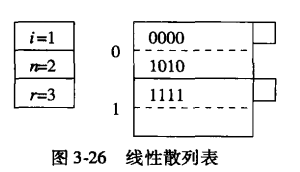
- i(当前被使用的散列函数值的位数)、n(当前的桶数)、r(当前散列表中的记录总数)
- (没怎么看懂)
- 优点:桶的增长较为缓慢
多维索引
- 数据结构:类散列表方法,类树方法
多维数据的散列结构
- 网格文件:通过排序该维的值来划分该维
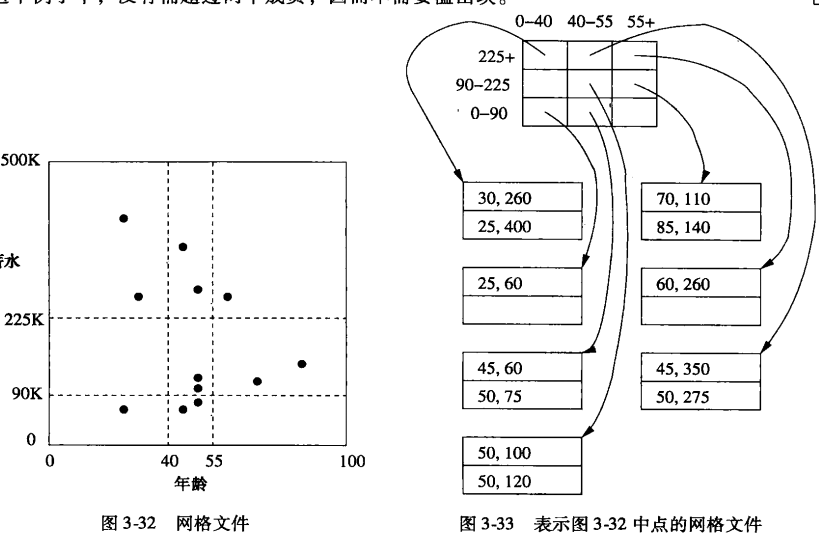
当数据分布性很好,且数据文件本身又不太大,那么可以选择网格线。
分段散列:为每个二进制位设定一个属性
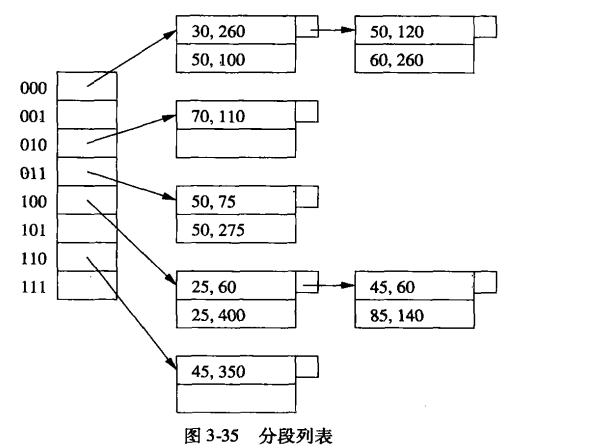
- 对最近邻查询或范围查询实际上没有什么用,因为点之间的物理距离并没有通过桶号的接近反映出来。
- 如果只需要支持部分匹配查询,只需要指定某属性的值而不指定其他属性,那么分段散列函数可能会比网格文件好。
多维数据的树结构
多键索引
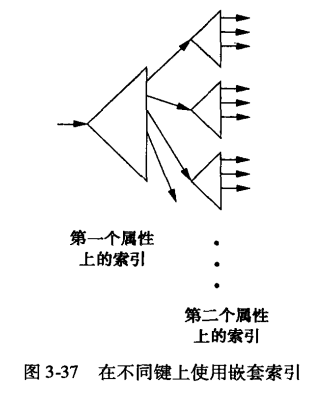
kd-树
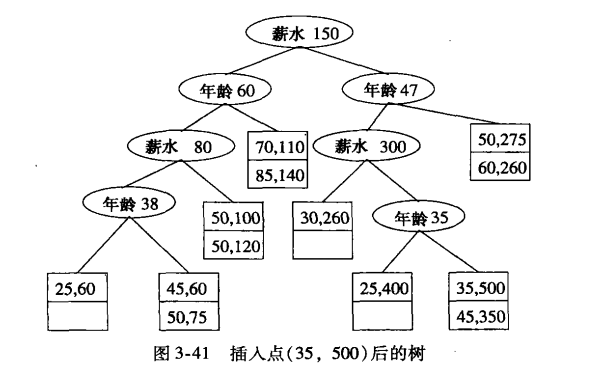
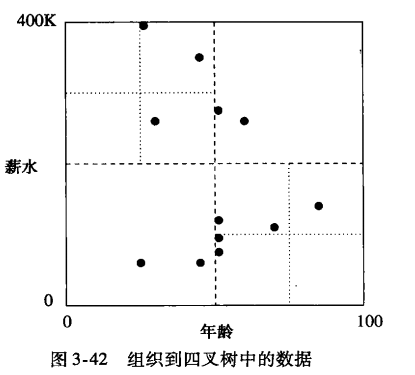
四叉树:根据象限来划分
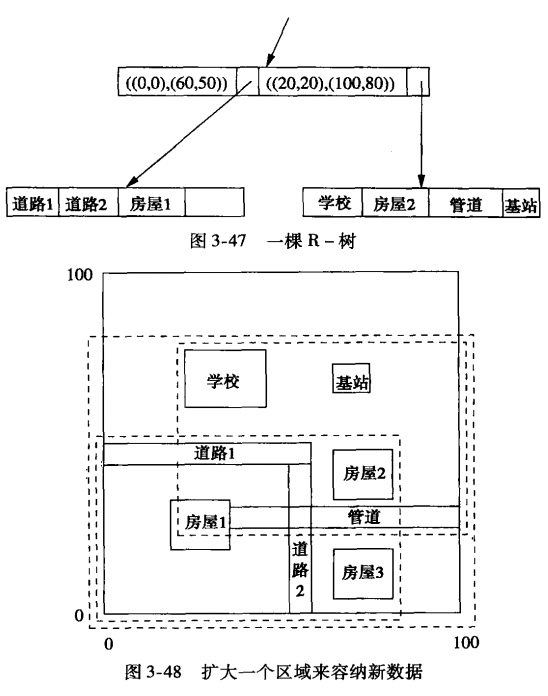
R-树(内部结点对应于某个内部区域)
- 对于”where-am-I”这类典型查询,R树是有用的。
位图索引
- 每条记录作为二进制位,针对年龄这个字段,如18岁,假定有6条记录可能在第1,2,3条记录的年龄为18岁,则位图表示为111000
- 压缩位图:采用分段长度编码
注: 一般做删除操作,都直接在数据文件中采用“删除标记”